Make Playwright faster: experimenting with containers and build caching on Github actions


 KarmaComputing
KarmaComputingBackground: We started using Playwright very early on, and had ended up with a test suite which was taking too long to run, and especially long on our pipelines (sounds familiar?). In the interest of a faster feedback loop (and fun). I was motivated to get up to date with the Parallelism and sharding capabilities offered by Playwright. We were attempting to take advantage of this, but had a cumbersome 'file splitting' approach meaning we, mere mortals had to manually divide up the tests into batches and files (manual work a computer can do, being done by humans- yuk!). tldr-almost: Parallelize tests in a single file will get you so-far, but read on for the real gains and understanding.
Before you read this
I was convinced that we could get better performance by not doing installs each time, and caching the container image using Github actions caching (obv... spoiler- I was wrong) and instead baking a container to just run the tests- If the test can run locally in sub 1 minute, then the pipeline should run time should not be excessively longer- ideally it should be faster (I fear this expectation is contrarian, and in many cases sure, longer pipelines can be inconsequential but a lot of the time pipelines are slow is due to sloppiness, or moreover lack of time for such fine tuning).
I've therefore attempted to set groundwork for the principles so that you don't have to investigate this, and if you value super fast automated playwright testing and care about shaving minutes off your build time (or melting the ice caps slightly less fast) then read on.
Whilst you can docker save and docker load your container image from Github actions cache. It turned our that the time it takes Github to pull from cache can be slow (restoring the container image from Github Actions cache took > 17 seconds):
Run actions/cache@v3
Received 0 of 647842497 (0.0%), 0.0 MBs/sec
Received 71303168 of 647842497 (11.0%), 34.0 MBs/sec
Received 159383552 of 647842497 (24.6%), 50.6 MBs/sec
Received 255852544 of 647842497 (39.5%), 60.9 MBs/sec
Received 352321536 of 647842497 (54.4%), 67.1 MBs/sec
Received 448790528 of 647842497 (69.3%), 71.2 MBs/sec
Received 545259520 of 647842497 (84.2%), 74.2 MBs/sec
Received 639453889 of 647842497 (98.7%), 76.1 MBs/sec
Received 647842497 of 647842497 (100.0%), 67.6 MBs/sec
Cache Size: ~618 MB (647842497 B)
/usr/bin/tar --use-compress-program unzstd -xf /home/runner/work/_temp/5636f716-7457-49a4-a26a-a4c547db4012/cache.tzst -P -C /home/runner/work/playwright-testing/playwright-testing
Cache restored successfully
Cache restored from key: cache-docker-playwright-testingSo I was upset to see that all this effort has taken me back to square one:
The non-containerised Playwright Github workflow would only take 1m 4s, which was 21 seconds faster than the containerised approach! How could this be?

Time was being eaten up by:
- The fetching of the Github Actions cache (+17 secs)
- Unpacking of the caches container image (+33 secs) due to
docker load(notepigzmay help here) - Starting the container & running the Playwright tests (+17 secs as well)
Make the image smaller, use alpine, use scratch, use distroless I hear you say! Yes, but this is where my motivation weans- remember this is Playwright, which supports a number of web browsers (WebKit, Firefox Chrome and others). I don't know how I would go about re-compiling those down and still be able to claim the browser automated tests are even slightly representative: We're testing end-user browsing at the end of the day- we're not wanting to validate some random arch to run Playwright + browsers in a tiny container image - though fun it would be.
So how to get to a 47 second Playwright run?
For the Playwright container based approach, it turns out to be faster not to cache the docker image and simply lean on the network speed of your docker pull (from ghcr.io) which on balance was faster than the Github Cache network fetch and eventual docker load. Looking at the transfer speeds both ghcr.io and Github's layer fetching use some form of network file transfer, so we're back to the Fallacies of distributed computing (Latency is zero, Bandwidth is infinite).
So I removed entirely the silly use of Github actions cache which cached / loaded the Playwright Docker image, and compared timings:
- Amazing, we're down to 1m 2secs on the container based approach / (alas; all that effort experimenting with docker image caching /loading was wasted)
- Even better: If you ignore the job setup/tear-down , then the run is only 47 seconds!
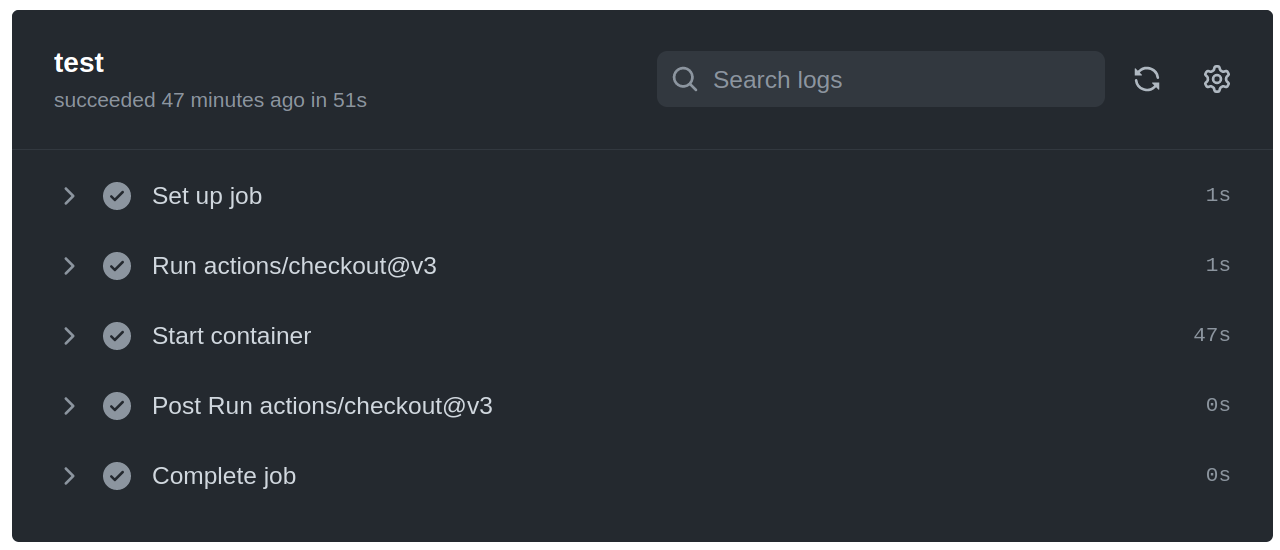
3. Not so great: All this effort and we've only shaved off 16 seconds off the non-containerised Playwright Github Actions which is documented in the official docs.
However, if you times that by how many times tests are ran... is that lot of electricity/time for you?
So far the key time saver which is helpful across both container and non-container based approaches for faster Playwright runs is to cache the Playwright browser download step:
- uses: actions/cache@v2
id: playwright-cache
with:
path: |
~/.cache/ms-playwright
key: ${{ runner.os }}-playwright-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
run: npm ci
- name: Install Playwright Browsers
run: npx playwright install --with-deps
if: steps.playwright-cache.outputs.cache-hit != 'true'
- run: npx playwright install-deps
if: steps.playwright-cache.outputs.cache-hit == 'true'Sharding Playwright Jobs
How to shard playwright jobs in Github actions to make test complete faster.
With the matrix Github Actions style piplines, you can shard and parallelize your Playwright test runs to make them even faster. The Playwright docs give sample examples for Github Actions, and GitLab CI (there's not sharding examples for Jenkins or Azure- it will likely be possible but it not documented). Here's the example Github Actions for parallelized test runs:
steps:
playwright:
name: 'Playwright Tests - ${{ matrix.project }} - Shard ${{ matrix.shardIndex }} of ${{ matrix.shardTotal }}'
runs-on: ubuntu-latest
container:
image: mcr.microsoft.com/playwright:v1.29.0-focal
strategy:
fail-fast: false
matrix:
project: [chromium, webkit]
shardIndex: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
shardTotal: [10]
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: '18'
- name: Install dependencies
run: npm ci
- name: Run your tests
run: npx playwright test --project=${{ matrix.project }} --shard=${{ matrix.shardIndex }}/${{ matrix.shardTotal }}Let's break that down.
Ultimately, the matrix syntax for Github actions gets fed two options:
- Project
- Shard number
They get passed into the Playwright cli for as many variations as there are (e.g. since we have chromium and webkit defined in the project matrix, test will run on both those browsers. The resulting command would look like
npx playwright test --project=chromium --shard=1/10
npx playwright test --project=webkit --shard=1/10
npx playwright test --project=chromium --shard=2/10
npx playwright test --project=webkit --shard=2/10
# etc...Will create many tests based on your matrix, and divide them among available Github / GitLab workers.
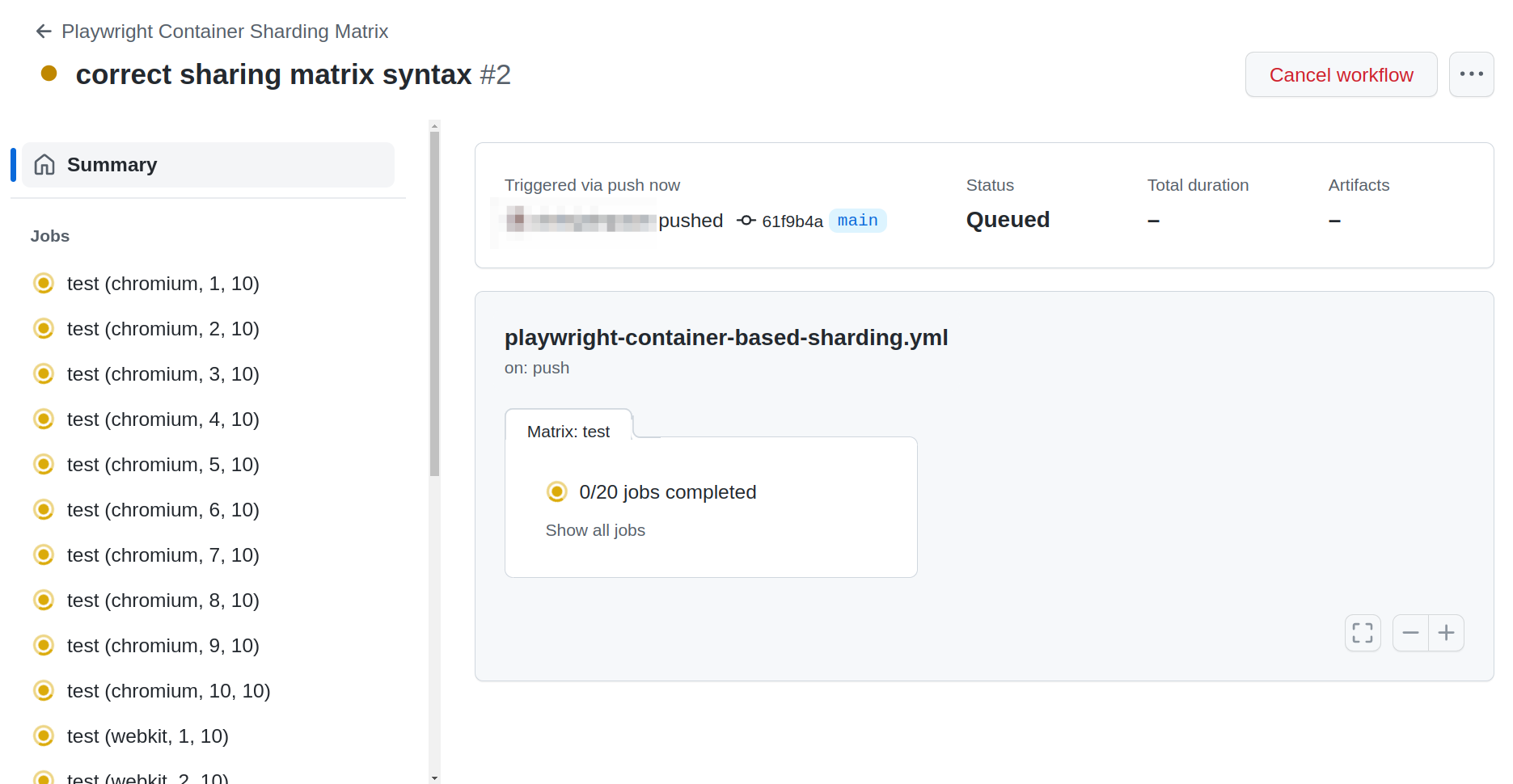
Use the fail-fast strategy to stop the job as soon as any of the jobs fail in the matrix - This will save your time (faster feedback loop), and the ice caps a little.
Here's what confused me: `--project <name>` refers to the browser vendor (Chrome, Firefox etc) which Playwright will use to run your test- at first glance I thought this meant my project or test suite.
See the Playwright cli reference for full command argument descriptions
How does Playwright sharding work?
--shard <shard> is also confusing if you're not used to it. In the cli docs it's described as " Shard tests and execute only selected shard, specified in the form current/all, 1-based, for example 3/5."
For example, in example.spec.ts there are 8 defined tests, and in playwright.config.ts we have enabled fullyParallel: true which caused Gitub actions to shard (aka split) the total number of tests across the available shardTotal.
Note, since we only had 8 example tests defined in commit 84dd55fd the shardTotal of 10 was actually wasteful since two Github agents (9 and ten) were not needed since there's only 8 tests to shard:
Run npx playwright test --project=webkit --shard=9/10
Running 0 tests using 0 workers, shard 9 of 10
Reducing down to 8 total shards removes the wasted cycles
Run npx playwright test --project=webkit --shard=8/8
Running 1 test using 1 worker, shard 8 of 8At this scale (8 tests) the time saving isn't noticeable - in fact it takes longer starting all these extra agents and containers. But that's because we have tiny tests , and so few.
So lets test 1000 Playwright tests & shard them using Github Actions Matrix
If you trust this list of the top 1000 websites, lets use that as our test basis. Bash to the rescue!
Let's use that file to generate a NodeJs set of PlayWright tests:
#!/bin/bash
OUTPUT="./example.spec.ts"
echo Remove existing $OUTPUT if present
rm $OUTPUT
touch $OUTPUT
echo Generating tests
curl https://gist.githubusercontent.com/bejaneps/ba8d8eed85b0c289a05c750b3d825f61/raw/6827168570520ded27c102730e442f35fb4b6a6d/websites.csv > top-1000-websites.csv
echo import { test, expect } from \'@playwright/test\'\; >> $OUTPUT
echo test.describe.configure\(\{ mode: \'parallel\' \}\)\; >> $OUTPUT
for WEBSITE in $(cat top-1000-websites.csv | cut -d ',' -f 2)
do
echo \test\($WEBSITE, async \(\{ page \}\) \=\> \{ await page.goto\($WEBSITE\)\; \}\)\; >> $OUTPUT
done
echo DoneWill generate a long test suite into a file called example.spec.ts:
$ head example.spec.ts
test("fonts.googleapis.com", async ({ page }) => { await page.goto("fonts.googleapis.com"); });
test("facebook.com", async ({ page }) => { await page.goto("facebook.com"); });
test("twitter.com", async ({ page }) => { await page.goto("twitter.com"); });
test("google.com", async ({ page }) => { await page.goto("google.com"); });
... etcReplace example.spec.ts with your new example.spec.ts if you're following along. Since we have enabled fullyParallel: true in our Playwright config, even multiple tests in one file like we have here will be parallelized.
Updating our Github action workflow to spread across 100 test agents:
KarmaComputingWhich spins up 200 agents (that's 100 for chromium and 100 for webkit thanks to the matrix support) to run all tests split across those agents:
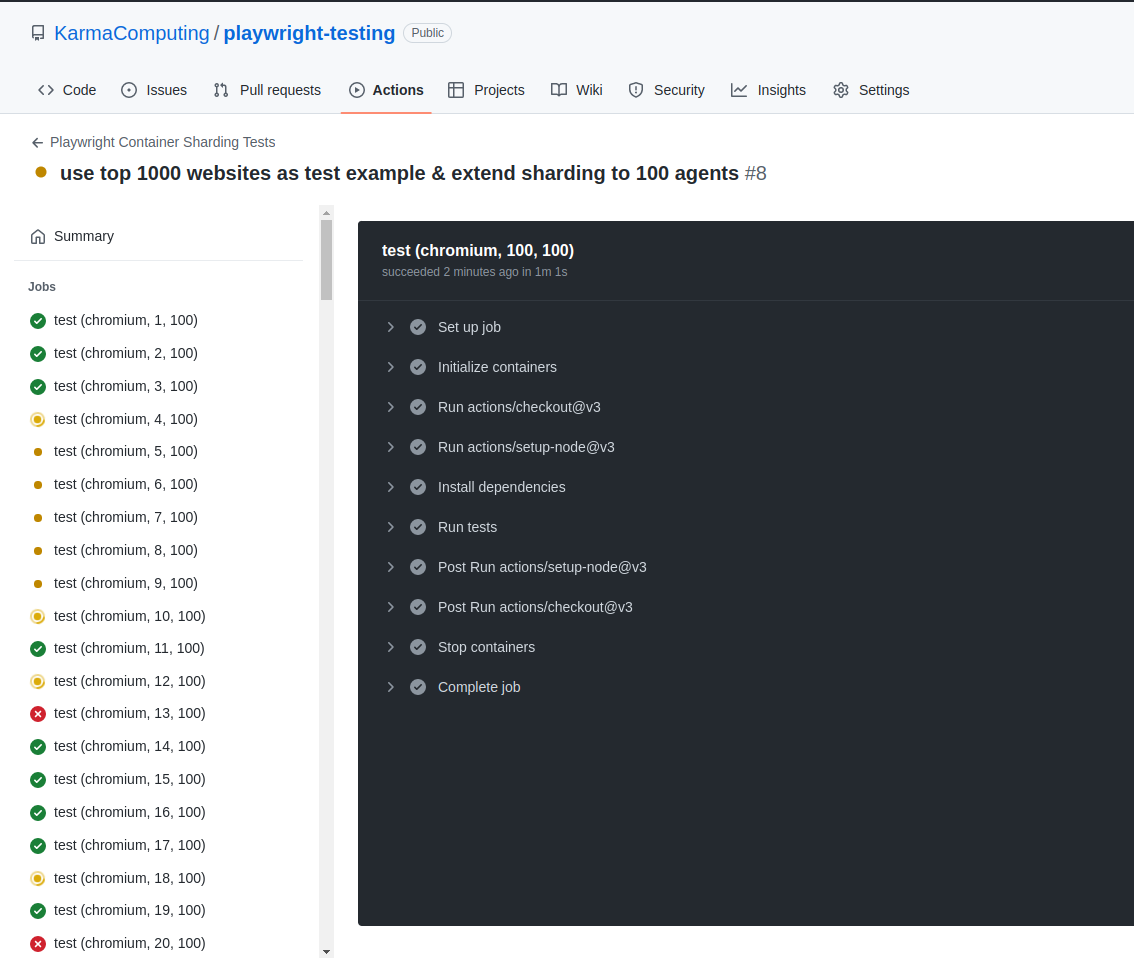
Naturally we start to see some errors with this higher sample rate (in reality these are due to Playwright not following all redirects). But it gives a taste of how you can use Playwright to make your tests suite faster with sharding.
Remember this isn't unique to Github, the same can be achieved on GitLab.