A practical, detailed guide to Git branching strategy, issue creation and merging

Question:
I would like to ask for an explanation about git best practices. Like git branching, naming branches etc
Sidenote- why does all this matter & why should I care about issues, git and branching?
Have you ever..
-
Not had enough information about an issue/bug?
-
Struggled to find a link to something? Don't have enough context?
-
Scared of a merge conflict? Confused about rebasing?
-
Not sure which issue the pull request is fixing?
Projects without standard procedures around issue creation and connecting that to git branching don't succeed, they eventually
grind to a halt and are left burning time & money away with 'issue management synchronisation tooling'.
None of these tools are needed. Tools cannot save you, the following disciplines can, and everyone can do it- it just relies on these effective communication strategies.
Answer:
0. Always start with an issue, not code
Contributions, changes, feature requests, & bug reports, must start with creating an issue, even if a tiny change. This gives you an issue number to use later on, and helps you & others quickly understand which issue a branch and commits relate to.
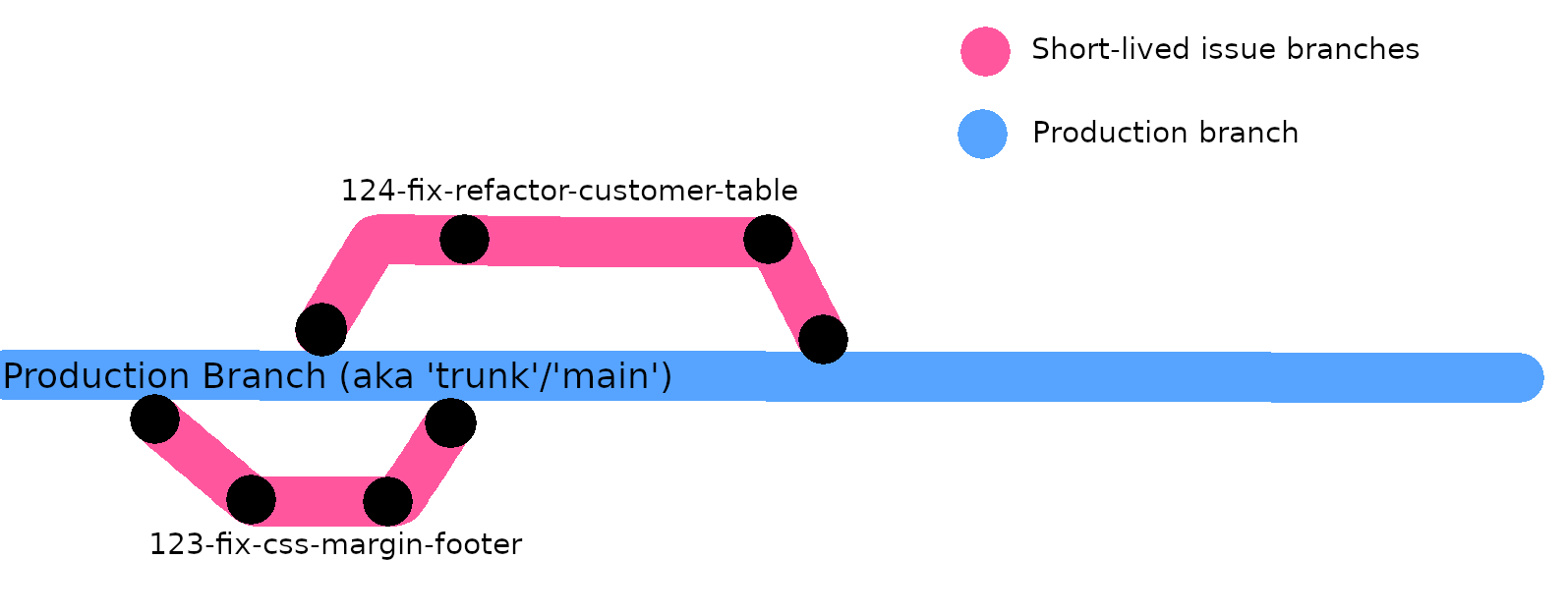
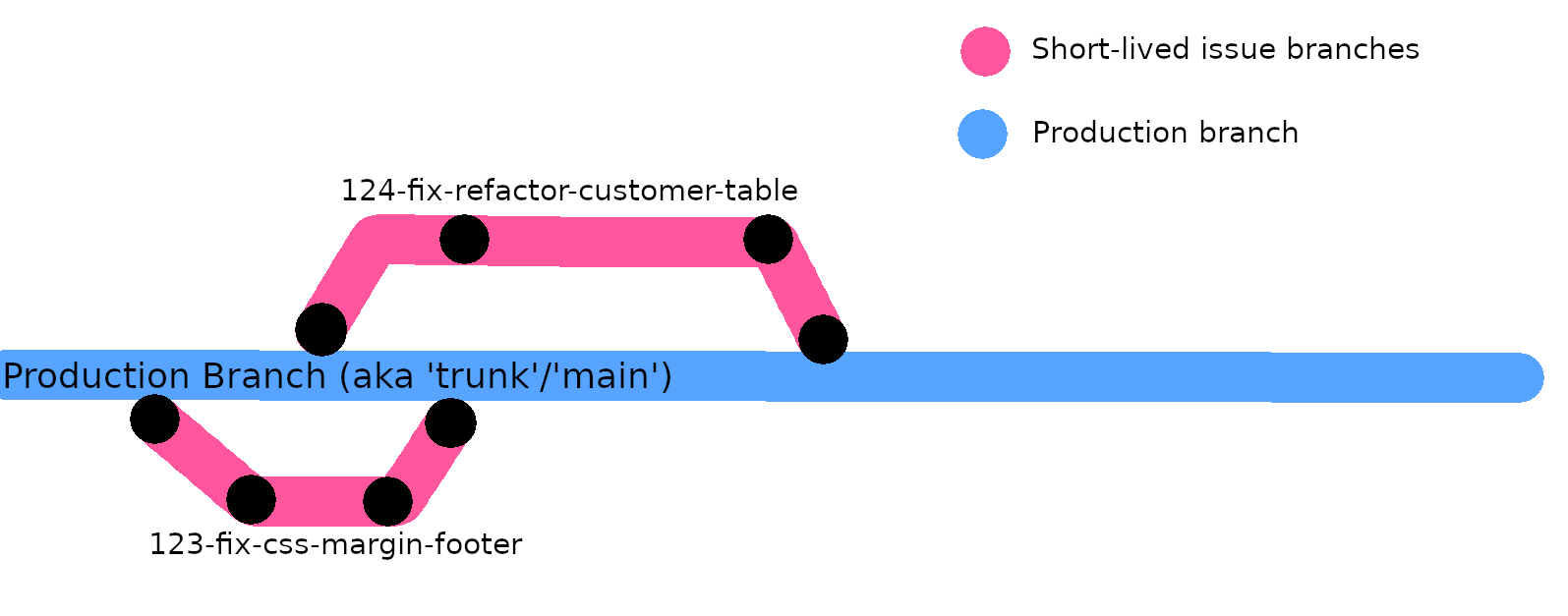
A branch, commits, (and the eventual pull request) are easily related to their issue(s) because you should name branches according to the issue number, and make commits
referencing the issue number (e.g. 123-fix-css-margin-footer). Such linking is mandatory because a reviewer must be able to relate the new code to the issue being fixed.
See also: Always start with an issue.
Here's a walk through of the entire process:
In this scenario you're about to work on a new issue, an issue has been created, and the issue number is 123.
You read the issue. If anything is unclear, such as a blank issue with a very vague title- then do not proceed to coding.
Instead, fail the issue as 'needs more information', and go find that information if you don't have it- it's everyone's responsibility to create clear issues.
If this seems extreme, consider the alternative- you proceed, not truly understanding the issue, code something for a few hours (days?) only to find the issue is:
- no longer needed
- a different problem to what was assumed
- tldr: Don't assume something you can check, and update issues when new information comes to light
If a sufficient issue is written, time to start branching!
1. Always branch off of the main branch
You'll likely have been busy working on a different issue, and it's likely other people have contributed changes to the main
branch whilst you were doing other work. You need to keep fetching & applying those changes to your local main branch. You
need to develop the habit of doing this often because the longer / further you stay behind the more irrelevant / out of date your
main branch is.
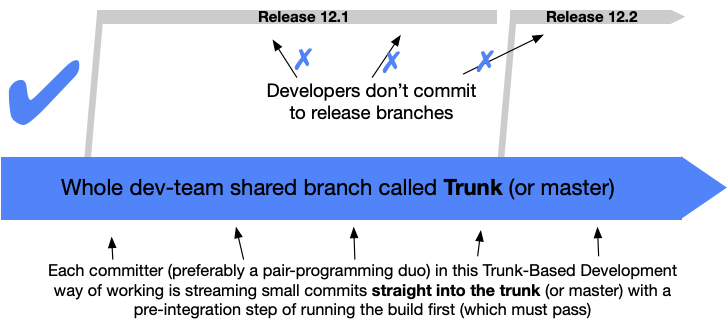
Question: What is
trunkwhat ismainand what ismasteranyway?
Answer: They're all the same- whichever branch holds your deployed code. In some
companies this might be calledprod,main,master- they're just names, the key
point is to always branch off of the main branch when you start new work on a new issue, because that's where the latest code is. Some people like the wordtrunkbecause it comes from the idea of a tree trunk 🌳, and all tree branches come out of the maintrunk. The key point is that you only ever create new branches off of the top of the trunk, which has the latest code (trees grow up).
Because your main branch may be out of date, update it with the latest code:
- Fetch the latest changes from
main:git fetch - Checkout to
mainbranch:git checkout main git fetch originfetches all changes into your local.gitfolder , but it does not change your files yet.git pull origin/main(this does change your files and brings them up to date withmain)Note you could do
git rebase origin/mainhere also- Create a new branch for the issue, using the number
git checkout -b -name-of-issuee.g:
git checkout -b 123-fix-css-margin-footer
The above creates a new branch, off of themainbranch. Remember, you're currently on themain branch, which is good because it contains the most up to date code because you just fetched and pulled
2. Push your blank issue branch & raise a PR right away (what?!)
Go to GitHub/GitLab/etc and raise a pull request for your new issue branch, which has no new code in it- yes really.
But why push a blank branch?
Pushing a blank branch should start your continuous integration (CI) pipelines and tests- which should all pass.
It is very valuable to start a new issue branch, raise a new PR and observe all checks pass before adding code because it establishes a baseline of all green in your CI & tests ✅✅✅.
If you see red at this point, this is a stop the production line moment- of course you can keep coding if someone else is investigating the CI build failures (but have you told them?).
git push origin 123-fix-css-margin-footer
Don't fall into the trap of coding away for days/weeks without pushing. If you work in a team, and you have a team lead- they'll be better informed if they have the possibility of seeing your code early in the process, and may even realise a different solution with you, saving you hours of your valuable time getting wasted.
Even if you don't work in a team- give yourself the early feedback that nothings wrong initially, and all your tests + CI pipelines are passing on this new branch.
It's not okay to release to production with CI build failures in testing, and ultimately that will need resolving before your PR may be merged.
2.5. Write a test to re-create the issue
Where reasonable, write a test which captures the issue. The test should fail to show the bug exists (and may give you a good idea of what might be the cause).
Keep pushing- at this point, you should see your beautiful pull request CI tests go from green ✅ to red ❌ because your test should be failing.
3. Code the fix/feature on this new branch- pushing little and often
Do your investigations/coding, creating small commits which reference the issue e.g. if you updated index.html file
git add template.html (or whichever files you changed)
# Commit your change
git commit -m "#123 wip css bug in footer"
When you use the "#" in a commit message, GitHub/GitLab/etc automatically shows a link to the related issue on GitHub/GitLab/etc issue. This is very useful for seeing the issue/code relationship. No fancy/expensive plugins needed.
When you say git commit -m "Fix #<issue-number> my comment about the code ", the issue gets closed automatically if the commit is merged into main on most systems (Git, Gitlab etc), (which saves time no longer needing to check 'is this issue closed?' etc).
4. Keep your issue branch up to date with main as you go
It's tempting to code away on your issue, forgetting that other code may get merged into main from another issue. You'll want to say up to date with those upstream changes.
tldr: Keep git fetching & pulling changes from main into your issue branch to stay up to date. This saves you time and pain in the long run because you learn about potentially breaking changes your fix will need to account for.
git pull origin/main (applies those changes to your current branch)
Pushing your issue branch:
git push origin 123-fix-css-margin-footer
5. Release the fix/feature, finally!
You'll know when you're ready to consider if you're done because you're:
- Pushing little and often
- Your CI checks should move from failing ❌ to passing ✅ again
- That is, the new test you wrote, if present, should be passing
Since you've already raised a pull request, all that's left to do is ask for a final review & merge!
Notes
Should I delete my branch?
No. There is no need to delete the branch remotely because branches are copy on write (very tiny file size) but locally you might want to delete them if you have hundreds or don't want to see them anymore (git branch -d)
Tip: It's normally a bad idea to delete a branch 10mins after raising a pull request, because you might need to add things later on. You can always get the branch back, it takes seconds, but it's a hassle. Just keep the branch locally, it's not causing any problems, it's helping you because you might want to go back to it in a few weeks.
Should I force push?
Never use force push if your working with others on a branch, it may destroy their work, and you'll have to dig through git reflog to get things back if possible. If you're not 100% sure, don't ever use force push. It's rarely what you want to do.
What about tagging multiple branches with a release 'tag?
No. The point is that branches are short lived. There is no long lived 'tagged' release branch. production (the latest commit to main) is the released version. If you are selling your software to multiple different customers who self install- then then this process is not sufficient (because you don't control their release process) but if you do, don't pin yourself to long long-lived tagged releases. Don't cherry pick into a 'release' branch- prod if the release branch already, and your pull request reviews, CI/CD process should have checks & balances in place to operate in that way.