Understanding Kubernetes

With containers, docker , Kubernetes etc I always have trouble working out:
- Where should I put my database?
- How do I handle secrets? (passwords, auth keys etc)
- How do we take an old, monolithic application and refactor it to work like this?
- How do I manage sessions? e.g persistant connections
- Most tutorials / accouncements focus on modern Node based applications and ignore systems which need to me remade or refactored
Pods , what?
Understand that pods may b be killed / fail at anytime. Operate upn this principle.
- Don't store persistant data in a pod
- Don't store persistant data in a container volume
- Both these stores are ephemeral
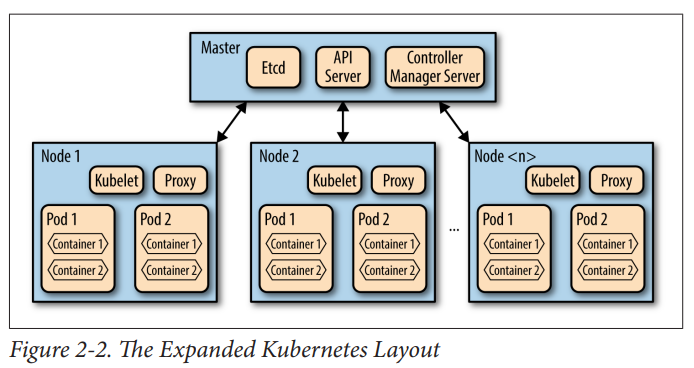
- Kubernetes from born out of Google Borg system, so much of the learning from the Google Borg System paper carry on (compare Figure 2-2 (Kubernetes) with Figure 1 (Google Borg)
Kubernetes:
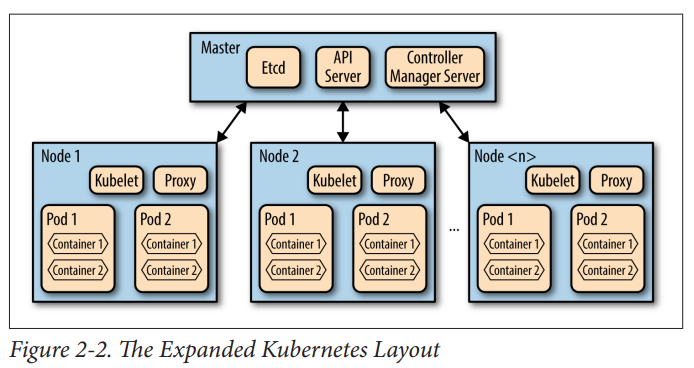
Source: Kubernetes: Scheduling the Future at Cloud Scale, David K. Rensin p.9
Whilst a pod can have a volume attached to it (and all containers within a pod can access a pod volume), a node failure or Kubernetes master itself may kill off these data stores at any time. (The Kubernetes master is where the Kubernetes replication controller is).
ie:
In addition, if you kill a replication controller it will not delete the replicas it has under management. (For that, you have to explicitly set the controller’s replicas field to 0.) <br /
Kubernetes: Scheduling the Future at Cloud Scale, David K. Rensin p.19
This behaviour dates back to Google's Borg system which also dosn't/can't/wont delete running nodes; this helps because if the master node dies, the worker noes can continue working until a new master is elected:
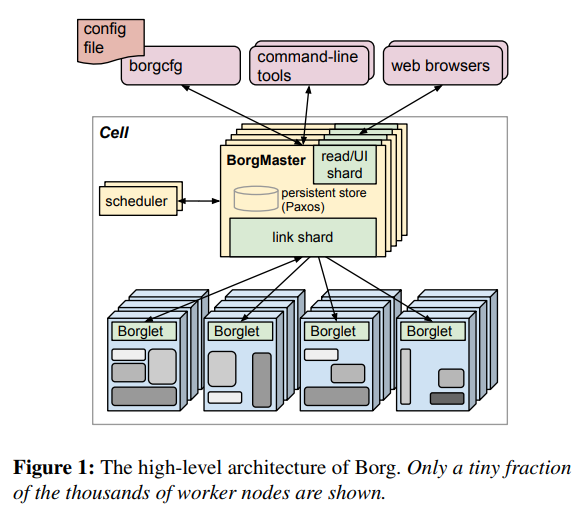
Source: Large-scale cluster management at Google with Borg (src) p.1
More information on Pod states.
Routing
First, there’s no guarantee that the pod that serviced one request will service the next one—even if it’s very close in time or from the same client. The consequence of that is that you have to make sure your pods don’t keep state ephemerally.
Kubernetes: Scheduling the Future at Cloud Scale, David K. Rensin p.23
How to do persistant storage kubernetes
How to handle the persistance layer.
Pods are not durable things, and you shouldn’t count on them to be. From time to time (as the overall health of the cluster demands), the master scheduler may choose to evict a pod from its host. That’s a polite way of saying that it will delete the pod and bring up a new copy on another node. ... Instead of storing your state in memory in some non-durable way, you should think about using a shared data store like Redis, Memcached, Cassandra, etc <br /
Kubernetes: Scheduling the Future at Cloud Scale, David K. Rensin p.11
^ That sounds great. HOW then, do I handle persistant data (like a database) in Kubernetes?
Kubernetes added the ability to mount an NFS volume at the pod level. That was a particularly welcome enhancement because it meant that containers could store and retrieve important filebased data—like logs—easily and persistently, since NFS volumes exists beyond the life of the pod
Kubernetes: Scheduling the Future at Cloud Scale, David K. Rensin p.14
Another option instead of NFS would be to use cephfs
Example Postgres cluster using patroni
Create and run a Postgres cluster:
git clone https://github.com/zalando/patroni.git
cd patroni/kubernetes/
sudo microk8s.docker build -t patroni .
sudo microk8s.kubectl create -f patroni_k8s.yaml
Connect to cluster
Fist get the generated service IP address, this will route to the postgres master:
# View generated statefulset pods:
sudo microk8s.kubectl get services; # look for patronidemo ClusterIP
Now get the super user password, and decode the secret:
By default, the patroni demo uses postgress/patroni
sudo microk8s.kubectl get secret patronidemo -o yaml | grep 'superuser-password'
Copy the returned secret and base64 decode the string. e.g:
echo 'emFsYW5kbw==' | base64 -d
# returns 'zalando'
Connect to psql cluster:
psql -h 10.152.183.220 -U postgres -p
# Enter password, you are connected!
# Create a database (automatically replicated):
# CREATE DATABASE test;
Secrets management
... https://kubernetes.io/docs/concepts/configuration/secret/
Create an deploy a helloWorld
1. Create docker image
Here's an example 'helloworld' app (guilty, yes this is a node app, based on the Kubernetes example) but not using minikube using microk8s instead.
2. Build it
microk8s.docker build -t localhost:32000/helloworld:latest .
microk8s.docker push localhost:32000/helloworld:latest
3. Create a deployment
sudo microk8s.kubectl create deployment hello-world --image=127.0.0.1:32000/helloworld:latest
4. Create service by exposing deployment
5. Build it
microk8s.docker build -t localhost:32000/helloworld:latest .
microk8s.docker push localhost:32000/helloworld:latest
6. Create a deployment
sudo microk8s.kubectl create deployment hello-world --image=127.0.0.1:32000/helloworld:latest
7. Create service by exposing deployment
kubectl expose deployment hello-world --type=NodePort --port=8081
https://itnext.io/microk8s-docker-registry-c3f401faa760 Comparing minikube and microk8s
https://kubernetes.io/docs/tutorials/hello-minikube/ Hello Minikube
https://microk8s.io/docs/registry Setup private registry
https://tutorials.ubuntu.com/tutorial/install-a-local-kubernetes-with-microk8s#4
https://itnext.io/a-local-kubernetes-with-microk8s-33ee31d1eed9
https://sdqali.in/blog/2016/11/04/a-very-basic-introduction-to-deploying-a-java-application-using-kubernetes/
sudo microk8s.docker build -t localhost:32000/obpapi:latest
sudo microk8s.docker push localhost:32000/obpapi:latest
sudo microk8s.kubectl deploy obpapi --image=localhost:32000/obpapi:latest